Vocabulary Extractor
Introduction
Vocabulary Extractor is a program to split any text into individual words, summarizing information about each unique word. The information is presented in the form of a tab-delimited matrix, so that the results can be easily copied and pasted into a spreadsheet program like Excel. The method for segmenting the words is simply to find the longest match within the dictionaries loaded into the program. This works well in general, but fails for some character combinations by splitting in the wrong place. it also fails to make words out of terms that aren't in the dictionary, and instead treats these as unknown words (or unknown single Chinese characters).
Running the program
When starting the program, the active window will be the Source tab. Text in the target language (which can include foreign text) can be entered into this window in two different ways. In the first method, the Source tab functions like a normal editor, and data can be pasted into it and edited as necessary. The second method is to read data from one or more files. Select the File->Open menu item to open the file window. Navigate to the proper directory and select the desired file. Using Control + click, you can select multiple files to open at the same time. After clicking the Open button, the file(s) will be loaded into the editor window, and multiple files will be loaded in the order they were selected. Each file will include a heading with a special character and the file name. This can be useful in the summary window, as it marks the places where new files are encountered throughout the running vocabulary list.
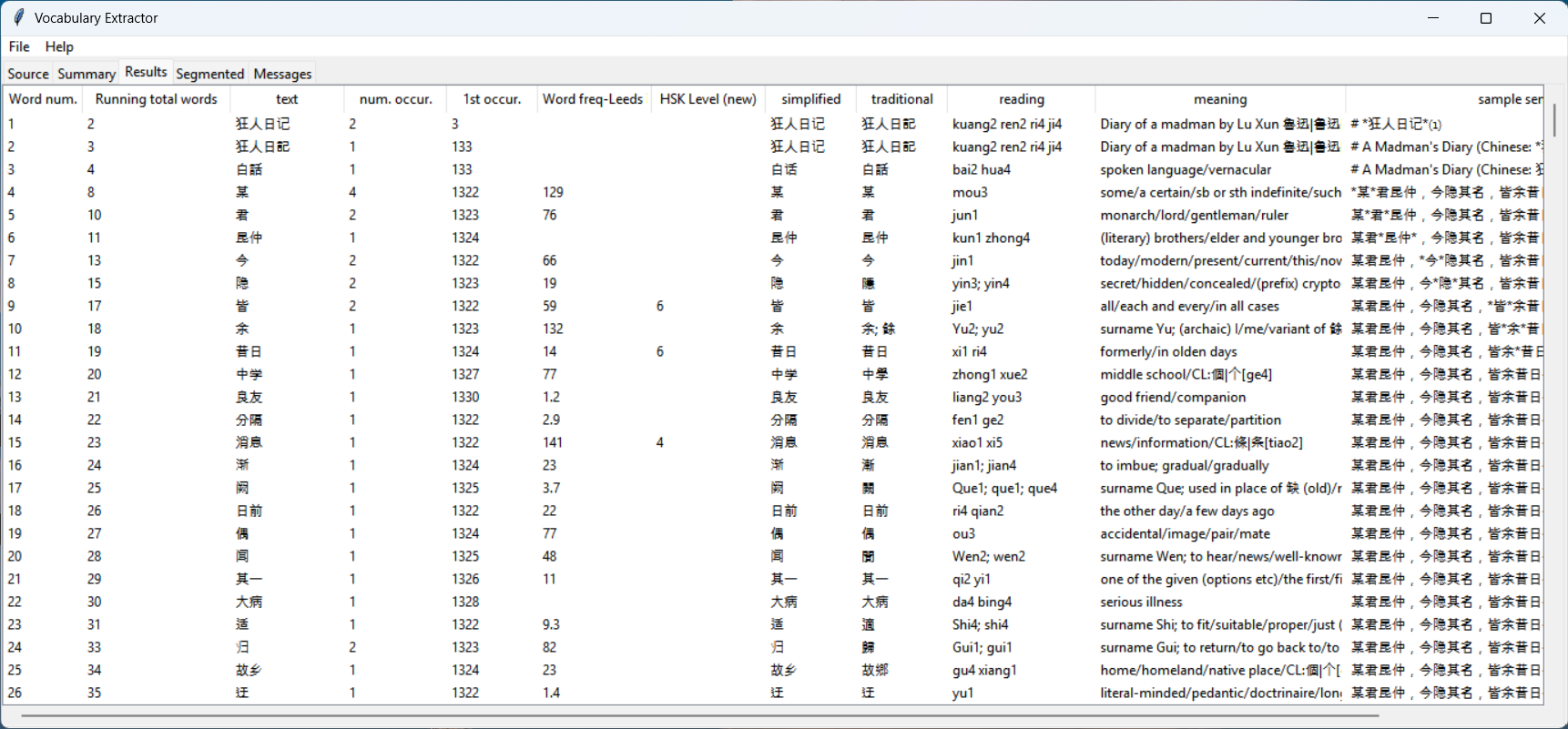
With data in the Source tab, now select the File->Analyze menu item. A progress bar will show how the analysis is proceeding, but may be too fast to see for small amounts of text. When the analysis completes, the Results tab will be filled with data on each unique word found. Some of the columns are:
- Word Number: An incremental count of Chinese words, not including non-Chinese words or words not in the dictionary
- Running Total Words: The sum of the total occurrences for this word and all previous words encountered
- Text: The original word
- Number of Occurrences: Number of times the word occurs in the text
- First Occurrence: The character position of the first occurrence
- Traditional: Traditional variant of the word as defined in the dictionaries used. All variants will be listed if there are multiple mappings
- Simplified: Simplified variant of the word as defined in the dictionaries used. All variants will be listed if there are multiple mappings
- Pinyin: Pinyin pronunciation as defined in the dictionaries. All values will be listed if there are multiple entries
- English: English definition as found in the dictionaries
- Sample Sentence: The first sentence the word was found in, with the word isolated by asterisks
To export the Result data, simply highlight all the data using Control-A, and copy it to the clipboard. The contents can be pasted directly into Excel or another spreadsheet program for further analysis.
Section breaks
The § character (section sign, Unicode U+00A7) is a special delimiter recognized by the program when it appears in source text. It marks a boundary between sections, preventing words from being counted across that boundary and causing a separator line to appear in the Results tab at that position.
The syntax is:
§ [optional label]The label, if present, appears in the separator line in the Results tab. When multiple files are loaded via File->Open, the program automatically inserts a § [filename] line between each file, which is why each file shows "a heading with a special character and the file name" in the results.
You can also insert § manually in the Source tab to divide a single file into named sections. For example, a file containing multiple articles from a series could use § [Article 1], § [Article 2], etc. to keep the sections visually distinct in the results.
Setting preferences
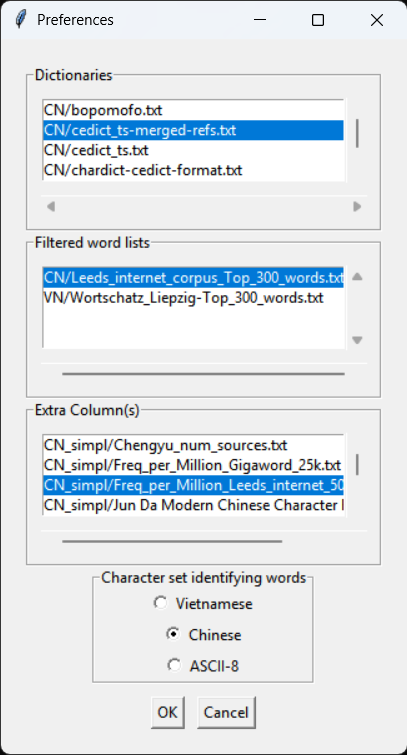
By selecting File->Preferences, you can manage the current settings of the program.
One or more dictionaries can be set active by highlighting them; use Control+click or Shift+click to highlight multiple dictionaries. The "Filtered Words" (see below) list allows you to select files containing lists of words to be filtered out of the results. The Extra Column(s)" (see below) list allows you to add extra column data to the results tab. Extra Column files are specific to simplified/traditional character sets, while dictionary and filtered word files work with either traditional or simplified texts.
The Character Set option sets the program to analyze the text as using simplified or traditional characters, using the appropriate simplified/traditional entry in the dictionary(ies) to identify words. Note that because extra column files are specific to a character set, the Extra Column(s) will change, and must be reselected (even if the names are identical).
Updating dictionaries
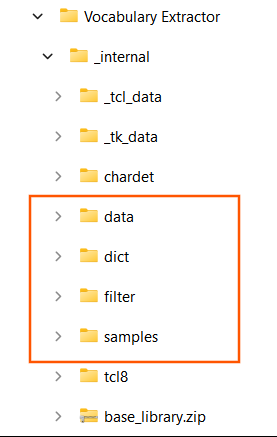
Dictionaries are stored in the program subdirectory "dict". A CC-CEDICT dictionary and VNEDICT dictionary is included with the program, and any dictionary in the CEDICT format (traditional simplified [pinyin] /English/definitions/) or EDICT format (word : definition) can be used as an additional source of definitions. All dictionary files must be in Unicode UTF-8 format. The first line of the file specifies the format of the definitions, for example `#%format: edict`.
Dictionaries or other files in the dict directory which are named with a leading underscore "_" will not be listed in the Preferences tab. This can be useful for documentation files or dictionaries temporarily on hold.
Adding filtered word lists
When using this program for creating vocabulary lists, it is often useful to automatically exclude well-known words from the results. Filtered word files are simply lists of words, one per line, saved in the filter/ subdirectory in Unicode UTF-8 format. Words can be either simplified or traditional, or even a mix of both in the same file.
Files in the filter directory which are named with a leading underscore "_" will not be listed in the Preferences tab. This can be useful for documentation files or filters temporarily on hold.
Adding extra column data
Data used in the columns of the results are obtained from files in the program subdirectory "data", in specific subdirectories for simplified and traditional characters. Data in these files will contain two columns separated by a tab: the first column will be a word and the second will be a value associated with the word. In the results, an extra column will be added for any data files set to active in Preferences. For words defined in the file, the corresponding value will be inserted in the extra column. For words not listed, the data will be blank.
If there is a line in the file starting with the text "# Heading: ", the remaining text on the line will be used as the column heading in the results. If the line is not found in the file, the filename will be used as the column name.
Note on Unicode UTF-8 encoding
Some programs, when saving files in UTF-8 format, will insert as the first character in the file an extra character known as a byte-order mark (BOM). It's difficult to tell whether this character exists in the file without hex editors or other special software. This program will read dictionaries, filters, or extra column files as if the BOM were real data. This means that data on the first line of the file may not work as expected. If you are uncertain whether this is happening and want to protect against it, you can simply have a comment (a line starting with '#') as the first line of the file.
Command Line Usage
The program supports two command-line modes: interactive (default) and headless.
Interactive mode launches the GUI as normal. --inputfile pre-loads a file into the Source tab. --config points to an alternate configuration file, which can be used to start the program with different dictionaries or a different character set.
Headless mode (--headless) skips the GUI entirely and writes tab-delimited results to a file or stdout. This is useful for automation, scripting, or batch processing. --inputfile is required in headless mode; output goes to --outputfile or stdout if that option is omitted.
Run with --help to see all options:
python main.py --helpOptions
| Option | Short | Description |
|---|---|---|
--headless | Run without UI; requires --inputfile | |
--inputfile PATH | -i | Path to input text file |
--outputfile PATH | -o | Output file for tab-delimited results; use - for stdout (default in headless mode) |
--config PATH | -c | Path to config file (default: ~/.Vocabulary Extractor/config.db). Loaded as baseline; other options override it. |
--dict PATH | Path to a dictionary file. Can be used multiple times. | |
--charset VALUE | Character set: Vietnamese, Chinese, or ASCII-8 | |
--filter PATH | Path to a filter (known-words) file. Can be used multiple times. | |
--extracolumn PATH | Path to an extra column data file. Can be used multiple times. | |
--appdir PATH | Base application directory containing dict/, data/, and filter/ subdirectories |
When --config is combined with --dict, --charset, --filter, or --extracolumn, the config file is loaded first as a baseline and the command-line values override the corresponding settings.
Paths supplied to --dict, --filter, and --extracolumn may be absolute or relative to the current working directory.
Examples
Run headless, output to stdout:
python main.py --headless -i samples/VN/mytext.txtRun headless with explicit dictionary, charset, filter, extra column, and output file:
python main.py --headless -i samples/VN/mytext.txt -o results.tsv \
--dict dict/VN/vnedict.txt \
--charset Vietnamese \
--filter filter/VN/known-words.txt \
--extracolumn data/VN/Freq_per_Million.txtStart the GUI with a pre-loaded file using a custom config:
python main.py -c myconfig.db -i samples/VN/mytext.txt